Cascade or direct speech translation? A case study
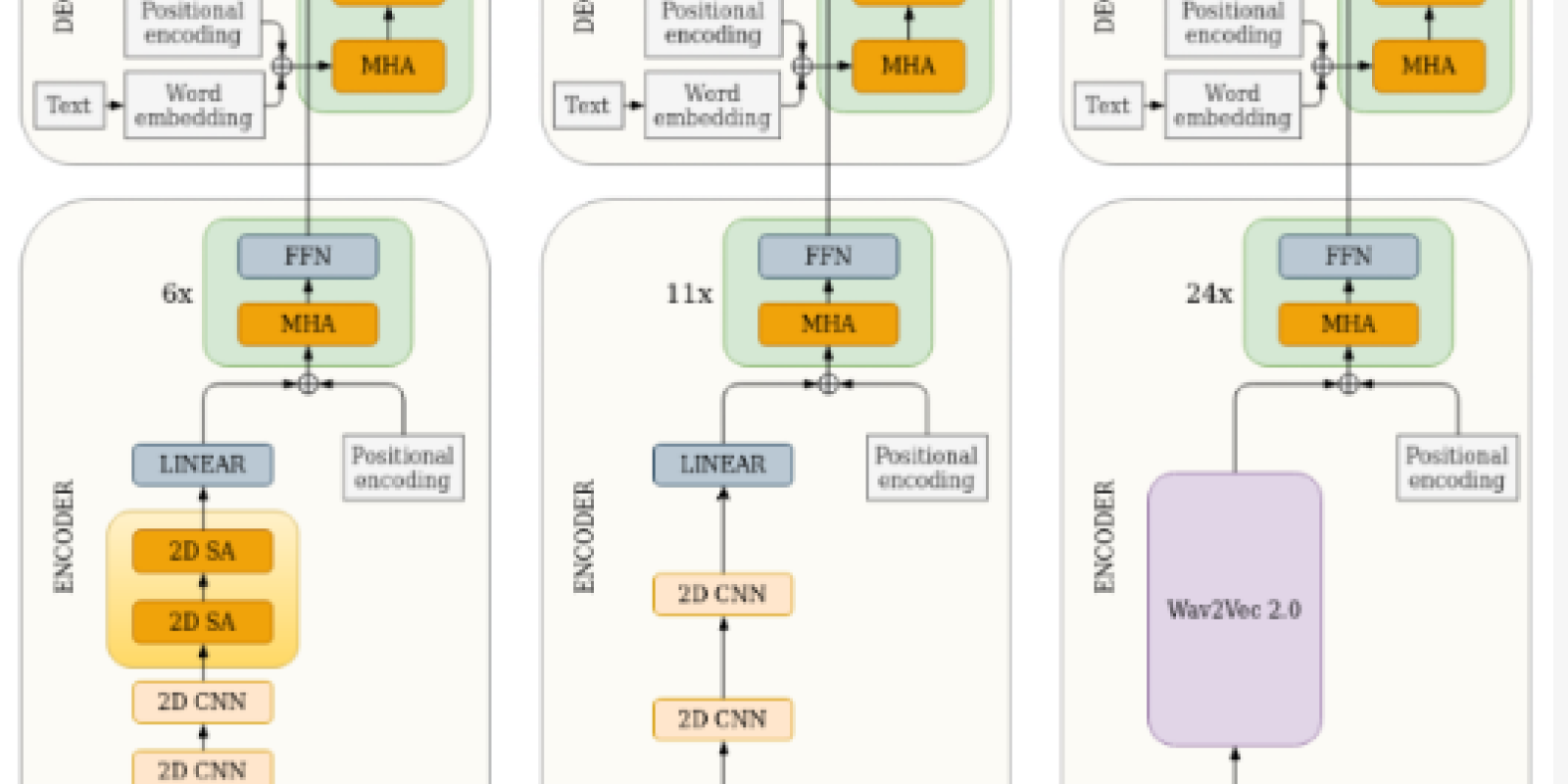
Speech translation has been traditionally tackled under a cascade approach, chaining speech recognition and machine translation components to translate from an audio source in a given language into text or speech in a target language. Leveraging on deep learning approaches to natural language processing, recent studies have explored the potential of direct end-to-end neural modelling to perform the speech translation task. Though several benefits may come from end-to-end modelling, such as a reduction in latency and error propagation, the comparative merits of each approach still deserve detailed evaluations and analyses. In this work, we compared state-of-the-art cascade and direct approaches on the under-resourced Basque–Spanish language pair, which features challenging phenomena such as marked differences in morphology and word order. This case study thus complements other studies in the field, which mostly revolve around the English language. We describe and analysed in detail the mintzai-ST corpus, prepared from the sessions of the Basque Parliament, and evaluated the strengths and limitations of cascade and direct speech translation models trained on this corpus, with variants exploiting additional data as well. Our results indicated that, despite significant progress with end-to-end models, which may outperform alternatives in some cases in terms of automated metrics, a cascade approach proved optimal overall in our experiments and manual evaluations.


