Transkit: automatic transcription based on neural networks
Transkit is a neural network based speech to text tool capable of transcribing audio and video content in Spanish, Basque or bilingual Spanish/Basque.
Tactical Objectives
For some years now, all trials, hearings, and meetings of the Basque judicial system have been recorded. These videos are made available to the different members of the judiciary so that they can review the sessions and complete their notes afterwards. However, this review can be a tedious and not very rewarding task when a large number of videos have to be reviewed.
Methods
Implementing this solution is not straightforward. The AI models need to be trained on a sufficiently large corpus of video and audio from court proceedings. This means that a significant amount of work needs to be done in terms of obtaining the necessary data and annotating it.
The current model is the result of manual annotation of 600 hours of generic recordings, 160 hours of domain content and over 500 documents with domain lexicon.
For the time being, and assuming that the AI-based solution does indeed make mistakes, this automatic process is called textualization in administration of justice, not transcription, and is used as a tool to help those professionals involved in transcribing or those who wish to rely on textualization to complete their notes in their daily work.
To objectively measure the quality of the model and its evolution, a measure called WER (Word Error Rate) is used, which is widely used to evaluate speech recognition systems. This calculation is based on obtaining the result of automatically transcribing a dataset, that has not been included in the training phase, and comparing this result with the manual transcription to find out what the deviation is.
The lower the WER value, the more accurate the results provided by the model.
Functional requirements
All of this development and improvement has been carried out in collaboration with a company specializing in AI called Vicomtech, as the Basque Government's IT department does not have the necessary skills to create models of this type.
A total of 12 people worked on the project: 1 project manager, 2 developer, 1 AI specialists, 1 DevOps specialist and 7 people to generate data from videos.
Results and Impact assessment
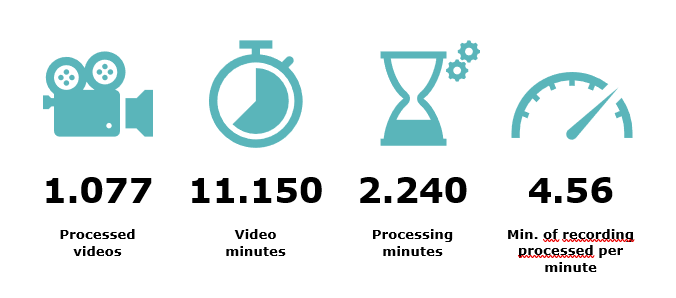
The speech to text service, which is already in production and integrated with the procedural manager of the Basque administration of justice, transcribes all the videos recorded in 12 different units in Vizcaya, Gipuzkoa and Alava. Around 11,000 minutes of video were processed in 2,000 minutes last October.
Dependencies and constraints
The implementation of Transkit presented several technological challenges that needed to be addressed.
In terms of infrastructure challenges, Red Hat Openshift is used as the Kubernetes platform to provide the solution with scalability and self-healing and, to run the artificial intelligence models created, graphics cards (GPUs) were installed in the Basque Government's CPD and supplied to the cluster of Kubernetes. The transfer of files between the different tenants is done via Scality S3. Server for Object Storage where each organ has its own private space.
In addition, it was necessary to integrate NVIDIA software (CUDA drivers) and VMWare virtual machines with support for vGPU. Transkit’s ASR and Diarization modules are based in Kaldi project

The quality and volume of the audio, the fluency, accuracy, speech and pronunciation of the speaker, and even the use of the mask at the time of COVID, all affect the quality of the transcript.
So, we cannot generalize when deciding whether this model of AI is good or bad, it depends very much on factors that sometimes cannot be controlled.


